-
目标:解决无约束优化问题:minx∈Rnf(x)
-
牛顿法:
f(xk+p)≈f(xk)+∇f(xk)Tp+21pT∇2f(xk)p
最小化该二次模型,可以得到搜索方向pk=−[∇2f(xk)]−1∇f(xk),然后逐步更新xk+1=xk+pk。该方法需要计算和存储Hessian矩阵和逆,计算复杂度O(n3) 3. *拟牛顿法:构造Hessian矩阵逆的近似Hk≈[∇2f(xk)]−1,理想情况下希望它满足拟牛顿条件:
Hk+1(xk+1−xk)≈∇f(xk+1)−∇f(xk)
- BFGS:
Hk+1=(I−ρkskykT)Hk(I−ρkskykT)+ρkskskT
其中sk=xk+1−xk,yk=∇f(xk+1)−∇f(xk),ρk=ykTsk1,避免计算Hessian,但仍然需要存储稠密的n×n的矩阵Hk
- LBFGS: 目标是计算pk=−Hk∇f(xk),而不显式的存储Hk。迭代流程如下:
- 保存最近m次的迭代对{si,yi},初始逆矩阵近似Hk0:通常为简单的标量矩阵,例如HK0=γkI,γk=yT∗k−1y_k−1sk−1Ty∗k−1
- 初始化q=∇f(xk)
- 对于i=k−1,k−2,⋯,k−m,令αi=ρisiTq,q=q−αiyi,r=Hk0q
- 对于i=k−m,k−m+1,⋯,k−1,令βi=ρiyiTr,r=r+si(αi−βi),最终得到的r就是我们想要的Hk∇f(xk),即pk=−r该方法的收敛速度为超线性收敛,空间复杂度为O(mn)
- 定义:假设地面上X=R2堆了一些石子,石子的分布我们用μ:X→R来表示,采取这样的表示方法对于地面上的任意一块面积A⊆X,μ(A)表示这块面积上放置了质量为多少的石子。同样的我们可以定义目标石子堆的分布ν。定义一个输运方案T:X→X把现有的石子堆变成目标石子堆。T(A)=B表示把原来放在A处的石子都运到B处放好,类似地可以定义反函数T−1(B)=A。该输运方案成立需要满足
ν(B)=μ(T−1(B)),∀B⊆X
即任意位置的石子通过输运过后都刚好满足分布μ的要求。这也可以写为T#μ=ν。由此,两堆石子之间的距离可以被定义成把一堆石子挪动或另外一堆所需要的最小输运成本
Wp(μ,ν)=(T:T#μ=νinf∫X∥x−T(x)∥pμ(x)dx)1/p
对于石子不可分的情况,我们有如下公式
W2(μ,ν)=(γ∈Γ(μ,ν)inf∫X×Yd(x,y)2dγ(x,y))1/2
- Γ(μ,ν)是所有联合分布的集合,其边缘分布分别为μ和ν, d(x,y)是x和y之间的距离度量, γ表示如何将分布μ"传输"到分布ν. 一维情况下有如下公式:
W22(P,Q)=∫01∣F−1(u)−G−1(u)∣2du
其中F和G为相应的概率分布函数
- 一维情形下我们有如下的闭式解:
Wpp(P,Q)=∫01∣F−1(u)−G−1(u)∣pdu
F和G分别为与P,Q对应的分布函数。离散情况下,假设我们有从P中取出的N个样本{x1,⋯,xn},从Q中取出的N个样本{y1,⋯,yn},我们有经验分布函数:
FN(x)=N1i=1∑N1{xi<x}
相应的有经验分位数函数
FN−1(u)=x(k),Nk−1<u≤Nk
同理可得G−1(u)。由此我们有
Wpp(PN,QN)=∫01∣FN−1(u)−GN−1(u)∣pdx=k=1∑N∫(k−1)/Nk/N∣x(k)−y(k)∣pdu=N1k=1∑N∣x(k)−y(k)∣p
- 二维情形可以采用如下两种方法: 1. Sliced Wasserstein Distance:将二维分布做投影到一维分布,然后对一维分布投影计算相应的W2距离,然后做积分。具体的数学公式为
SWp(P,Q)=(∫Sd−1Wpp(Pθ,Qθ)dθ)1/p
其中Pθ为P在方向θ上的一维投影分布:
Pθ=Distribution of θTX,X∼P
实践中我们采用随机采样方向来近似这个积分
SWp(P,Q)=(L1l=1∑LWpp(Pθ,Qθ)dθ)1/p
也即我们先随机生成L个随机方向θ1,⋯,θL∈Sd−1, 然后将P中样本{x1,⋯,xN}⊂Rd,Q中样本{y1,⋯,yN}⊂Rd分别在这L个方向上做投影(也即做点乘),得到的投影值即为新的一维分布,这样就可以按照上面的一维情形求解了2. sinkhorn:引入熵正则化。原始的离散Wasserstein 距离需要解线性规划:
Wpp(P,Q)=γ∈Γ(P,Q)mini=1∑mj=1∑nγijCij
其中Cij=∣xi−yj∣p,∑jγij=pi,∑iγij=qj,γij≥0。sinkhorn引入熵正则化:
Wp,ϵp(P,Q)=γ∈Γ(P,Q)min[(i=1∑mj=1∑nγijCij)−ϵH(γ)]
其中熵H(γ)=−∑i,jγij(logγij−1),该问题有显式解
γ=diag(u)Kdiag(v)
其中Kij=exp(−Cij/ϵ),将该解代入约束可得
j∑uiKijvj=pi⇒ui=∑jKijvjpi
i∑uiKijvj=qj⇒vj=∑iKijuiqj
由此可以得到迭代公式u←Kvp,v←KTuq
波场是难以拟合好的,根本原因在于波场容易错开,具体来讲我们可以看下面的例子:
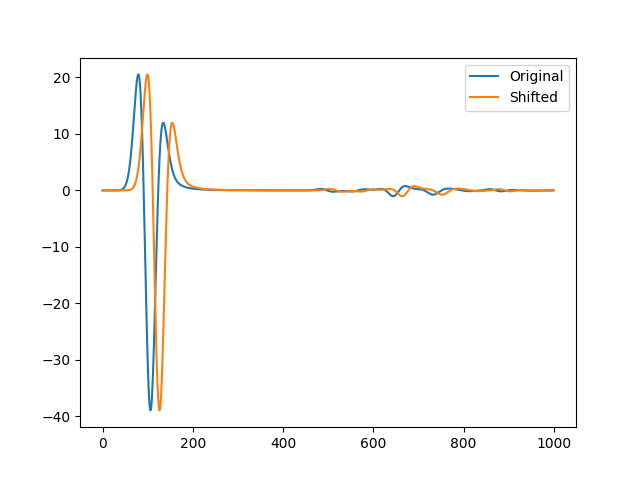
在这张图片中,我们可以看到橙色的波场是蓝色波场的一个偏移,在拟合的时候,梯度下降会优先将波做压缩而非平移,他并不知道平移的结果会使得误差函数降得更低。并且当偏移量足够大的时候,会发现MSE几乎不动,比如下面的图:
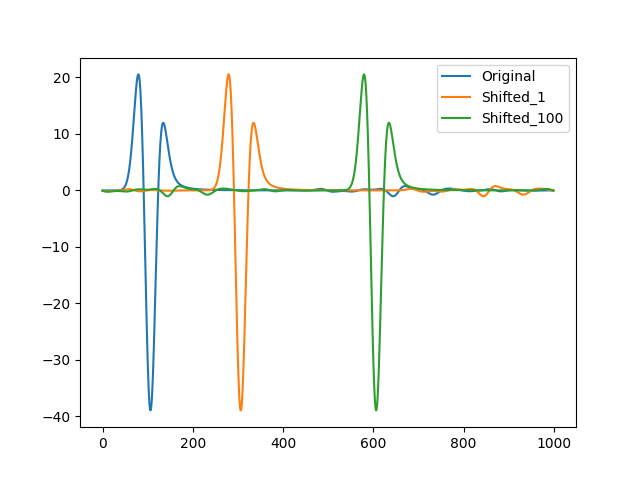
我们可以看到的是我们更想要橙色的波场,因为离蓝色的波场更近,但是计算橙色和绿色的波场的MSE都是差不多的,我们可以画出偏移量和MSE的关系图:
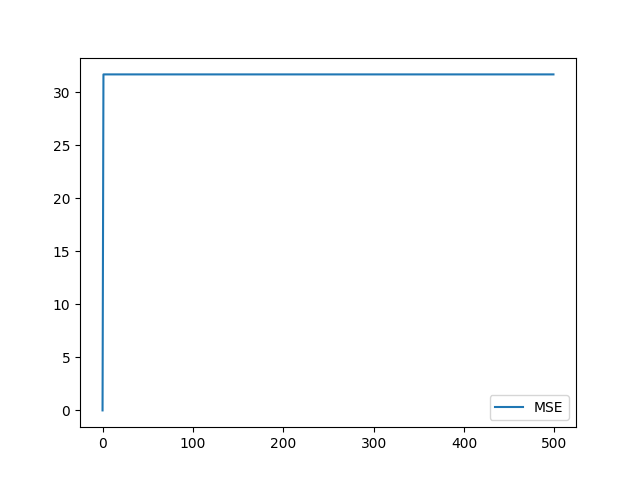
可以看到稍微大点的偏移量MSE几乎没啥改变。所以我们要想办法修改一下MSE。
如果波场都是正的,是不是我直接沿着x轴做cumsum就可以了?所以我尝试了一下取绝对值再然后再累积求和,具体的数学公式如下:假设我们有观测波场uo(t),合成波场up(t)(波场均为一维的),我们定义如下的距离:
d(uo,up)=∫0T(∫0t∣uo(s)∣−∣up(s)∣ds)2dt
果然解决了这个问题:
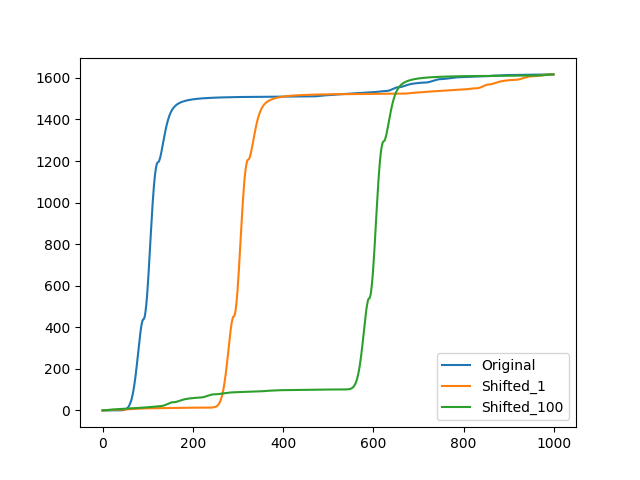
画出来的误差图像如下:
这个操作能解决波场偏移的问题,波峰的高低可能可以再用什么trick处理一下?实际实验似乎有那么一点效果,但应该还能改进(用这个误差dps好像试出来是有戏的)。有什么见解可以评论一下。这里会发现t比较小的时候的波场占比会比较大,应该可以再做某些调整。
W2的做法似乎也是差不多这个想法,把波场当成分布函数,但是波场这里不一定都是正的,是不是得有某些操作处理一下,而且我也没法从波场做采样。另外,个人感觉这里不应该当成二维图像做sinkhorn,而应该直接对那个1000维的向量求误差,再把总共的 5×70=350个都加起来。
- 如果有好的初值估计的话,无脑对逐通道使用W2,效果奇佳。
- 这里的W2使用的是加上波场的最小值再做归一化,直接取绝对值效果不佳
- 在没有好的初值的情况下,不管用什么损失函数,不管是否加tv正则化,都是寄(层数少的话用W2可能可以勉强做一做)。
- 在异侧的情况不见得比在同侧的情况好求解。
- 不推荐使用sinkhorn(不排除我参数没找好的情况)。
- 我现在也不知道哪个算子简单了,难以描述,建议看下面的结果。个人感觉如果本来初值的表面就很接近真实解的话(也即面波本来的误差就非常小),打点在表面甚至更好做。尤其是逐通道的W2.
- 不知道为什么积分loss失效了,完全跑不通(每次都是一开始相对误差就不下降,最后得到的图像也是完全不对的)(现在的结果我感觉是取绝对值的问题,换成W2那种减去最小值就能降了,还是能得到形状的,效果倒是没有W2那么好,当然不排除是调参的原因)
-
使用L2 norm: 1. Adam优化器:1. 初始化为真解的模糊化,具体公式为
output(x,y)=∬vtrue(u,v)1⋅G(x−u,y−v)dudv1
其中G为高斯核函数:
G(x,y)=2πσ21e−2σ2x2+y2
对应的离散格式为
output[i,j]=∑m=−kk∑n=−kkvtrue[i−m,j−n]1⋅G[m,n]1,G[m,n]=2πσ21e−2σ2m2+n2
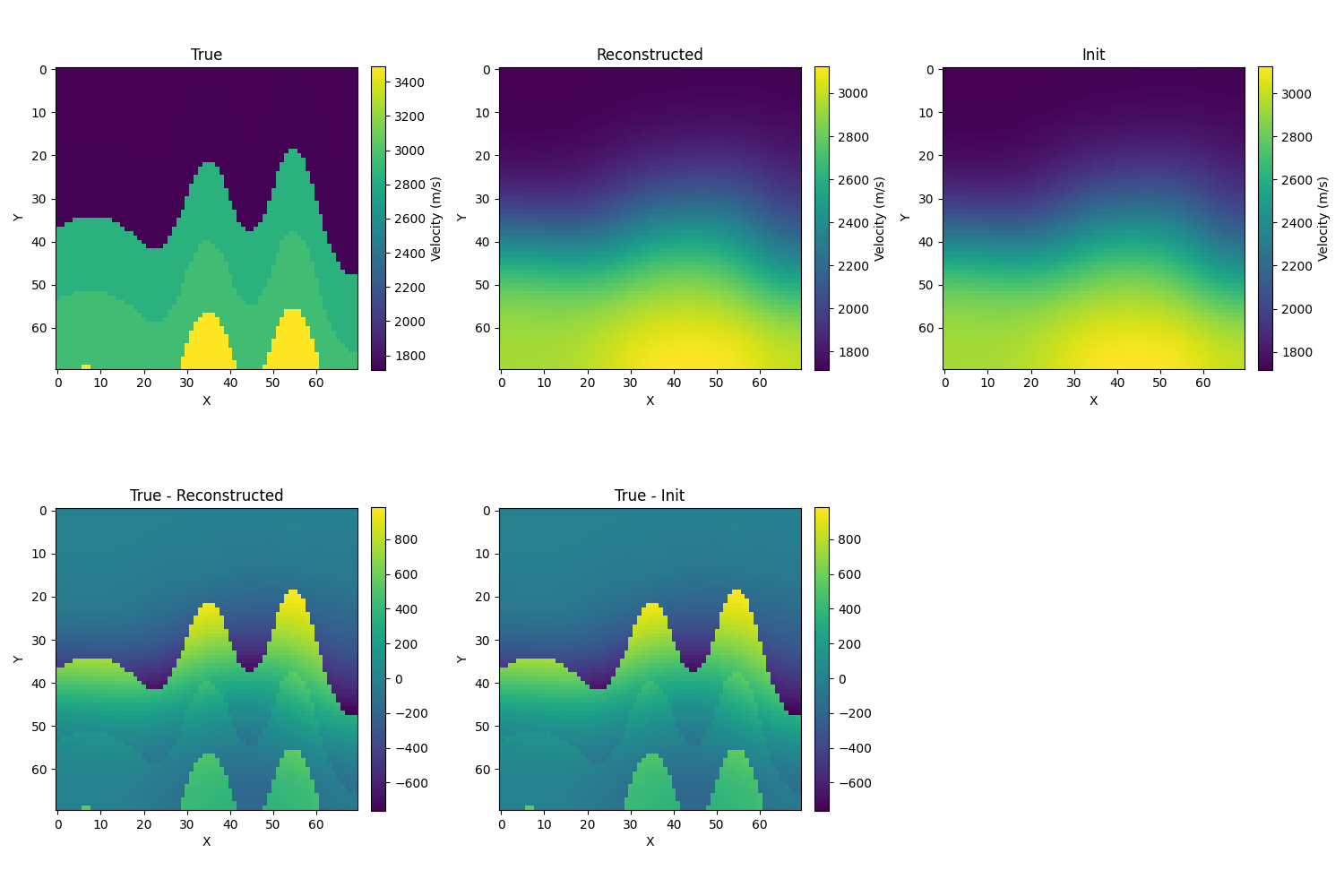
此处σ越大,初始解就越模糊,离真实解就越远。取σ=10,初始相对误差为12.1%,迭代的结果如下(分别为结果,解的误差,波场的误差),相对误差为7.7%(注意,此时并不会出现所谓半收敛性的线性的现象),相对误差虽然一直在降,但是很明显整个图已经脱离数据集了。理论上应该还能降)
- 取σ=100,初始相对误差为26.6%,迭代的结果如下,相对误差为26.7%
- 初始化为常数值(这里我取的中间值3000),也会在迭代后期出现上面速度太小导致的警告,虽然强行运行也是能得到一个结果的
这时我们就能明显地看到半收敛性现象了(当上面的σ较大时,也会出现相对误差不降的现象)> deepwave的建议是一个完整波形的长度至少需要6个网格点,否则可能无法准确模拟波形。根据波长=速度/频率,速度太小时,波长也会相应的小,所包含的网格点也就少,所以会出现上面的问题。此时在物理上无法进行有效的模拟2. SGD:结果有点amazing,相对误差几乎不带降,也就是基本没做移动(这里我学习率设置为50),把学习率调到5000,loss开始降了,但相对误差几乎不变(应该是在局部极小点附近了)
-
lbfgs优化(原来torch也是有lbfgs优化器的):我们继续重复上面的操作,结果也是很amazing,如果使用默认的使用 strong_wolfe进行线搜索,也会出现上面和上面SGD同样的情况。自己实现的lbfgs,使用原步长结果也是不太能动。
-
使用W2 metric(以下用的Adam优化器)
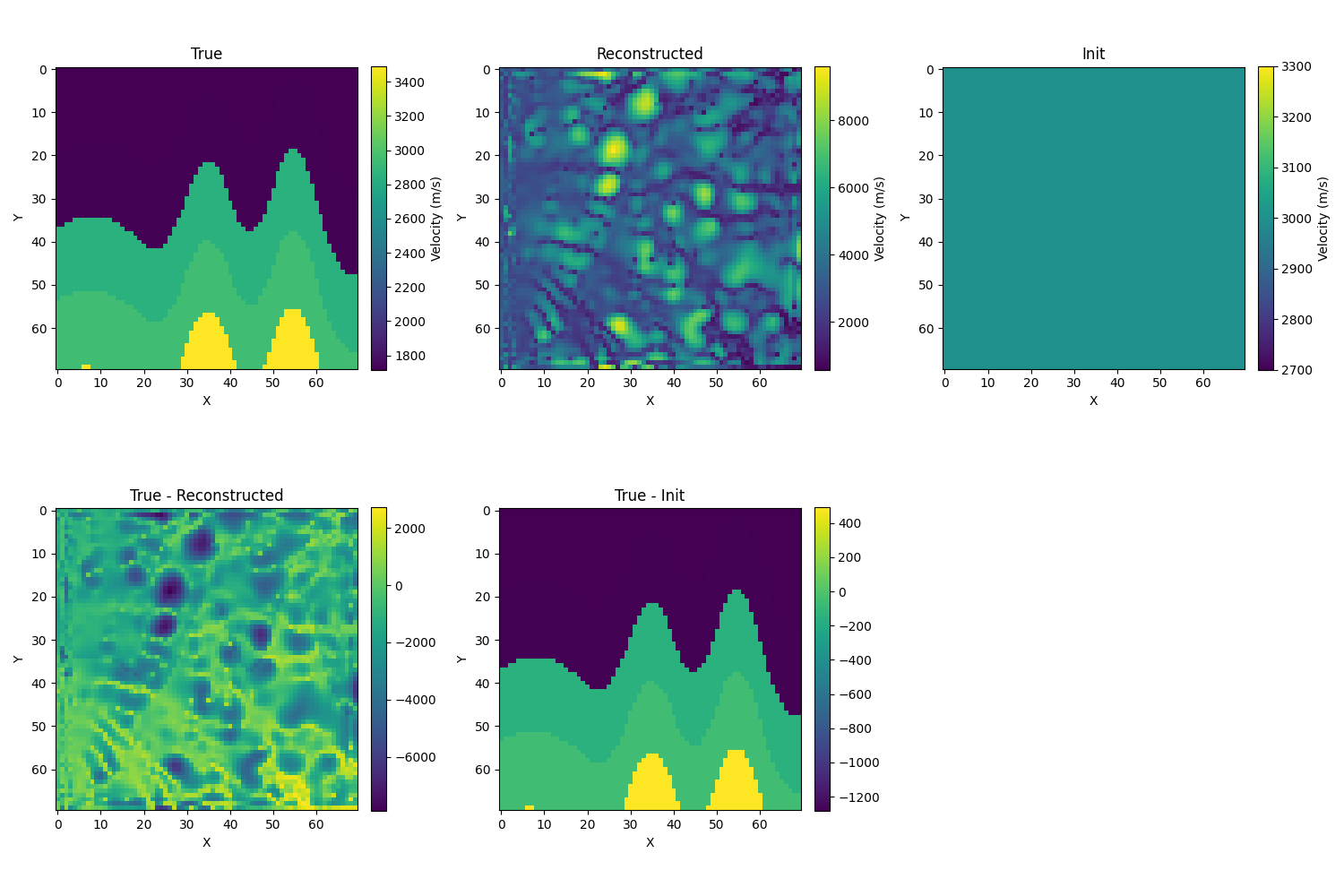
- 使用sinkhorn:初始解依然设置为真解的模糊化,使用adam优化器,σ=10时出现了速度过小的情况,而且是在前几步就出现了这个问题,后面的结果也不收敛。
-
把每个接收器和震源的pair对应的一维信号当作分布函数,直接求相应的分布函数,然后求逆,然后再直接计算误差
-
取σ=10,结果如下,相对误差为5.1%
-
取σ=100,结果如下,相对误差为22.1%
-
取初始值为常数值3000,结果如下
- 定义:增加一个惩罚项:图像梯度的L2范数
TV(u)=∑_i,j(u[i+1,j]−u[i,j])2+(u[i,j+1]−u[i,j])2
该惩罚项能促进梯度域的稀疏性。鼓励大部分像素梯度为0(平滑区),允许少数像素梯度很大(边缘),即保边去噪。此时的loss_func我们定义为:
J(c)=MSE(d,u(c))+λTV(c)
这里的d为观测到的波场,迭代过程中的速度场,u(c)为相应的模拟波长,λ为正则化项的系数(这里由于速度场的值本身比较大(1500~4500),所以必须取一个比较小的值(比如0.001就太大了,相对误差会一直上升)。2. 使用L2 norm
-
Adam优化器:
-
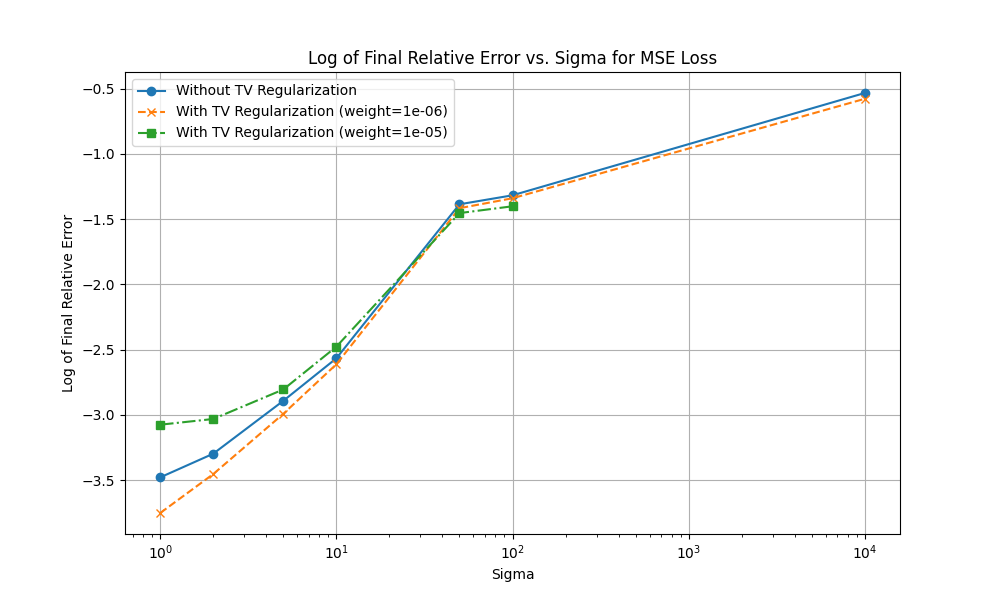
我们首先取λ=1e−6,σ=10,相对误差为7.3%,得到的图像如下。误差略微下降,并且图像看起来是会更接近数据集一点。
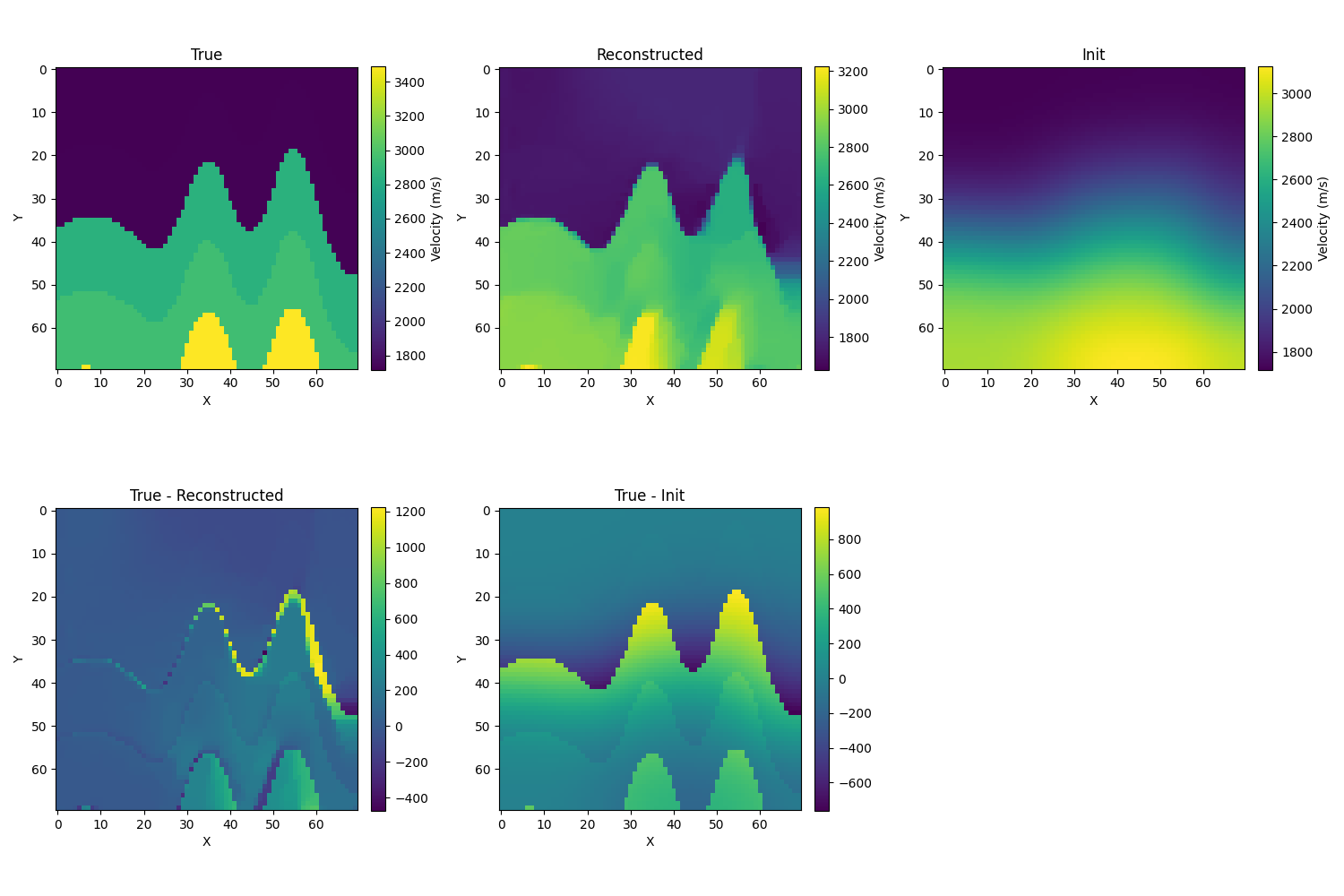
- 接下来取λ=1e−5,σ=10,相对误差为8.4%,得到的图像如下。误差反而增加了,d但图像看起来是会更接近数据集一点。
-
使用W2 norm
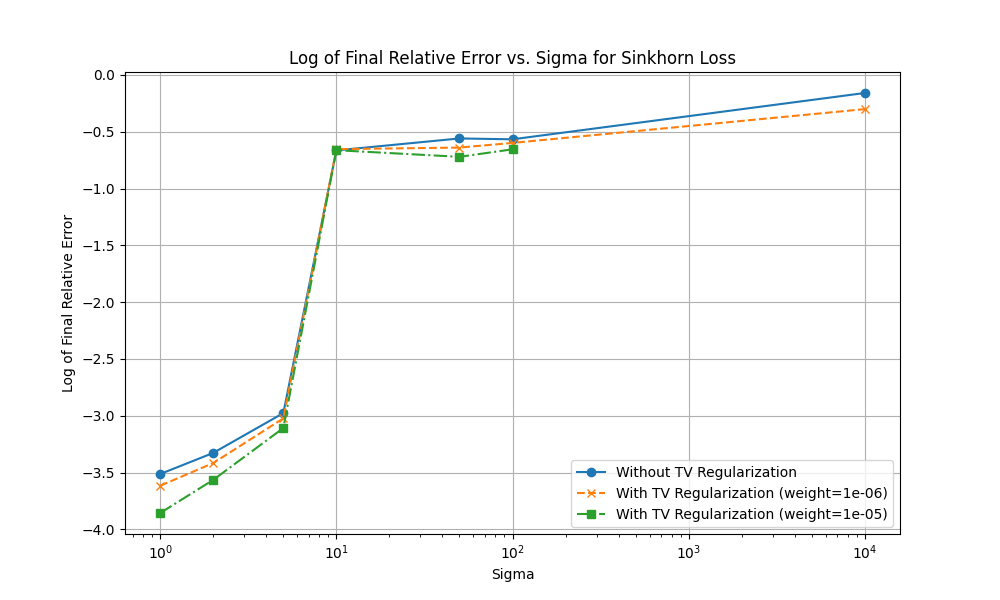
- 取λ=1e−6,使用sinkhorn: ,取σ=10,结果并没有得到改善:
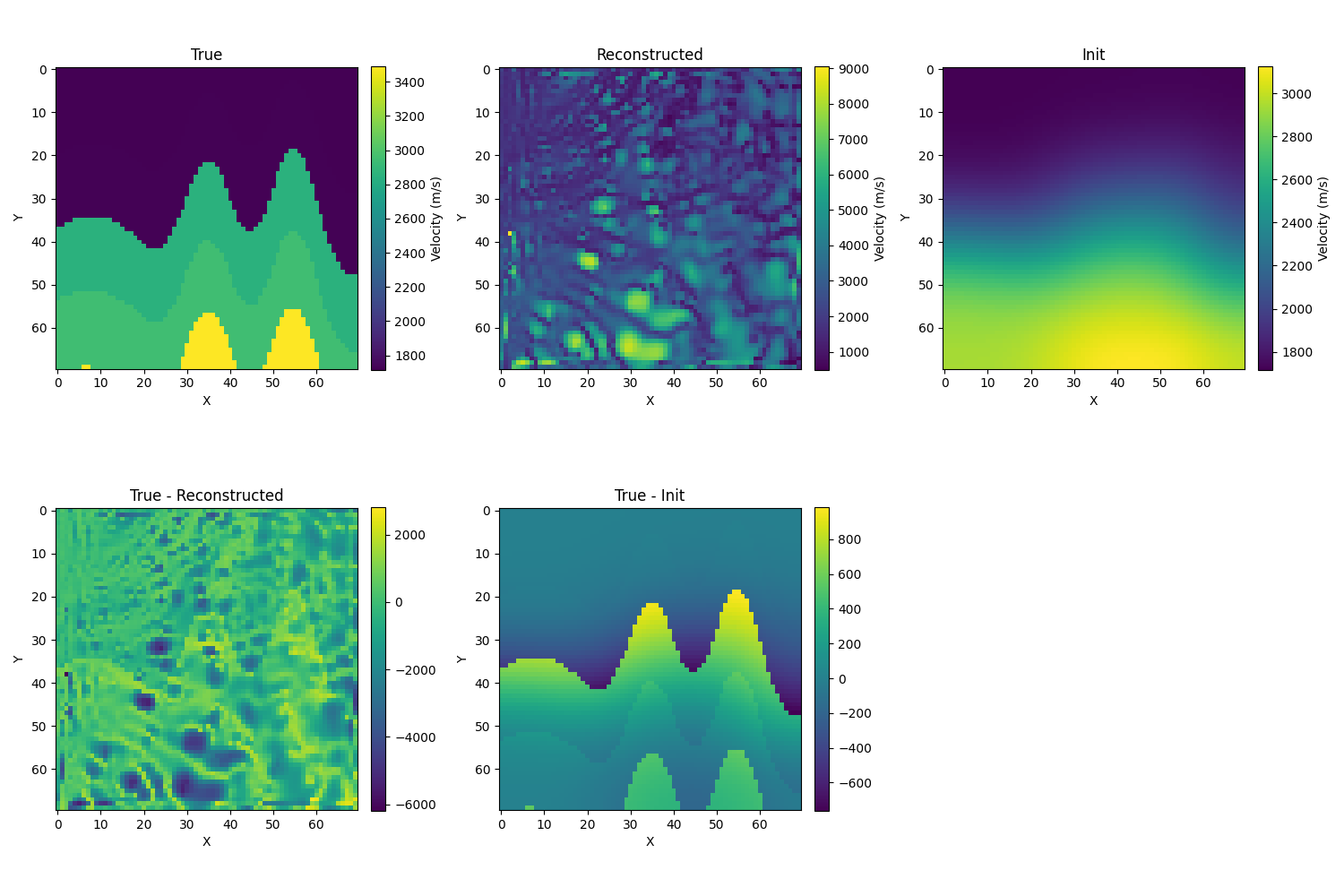
- 取λ=1e−5
- 使用sinkhorn: ,取σ=10,结果并没有得到改善:
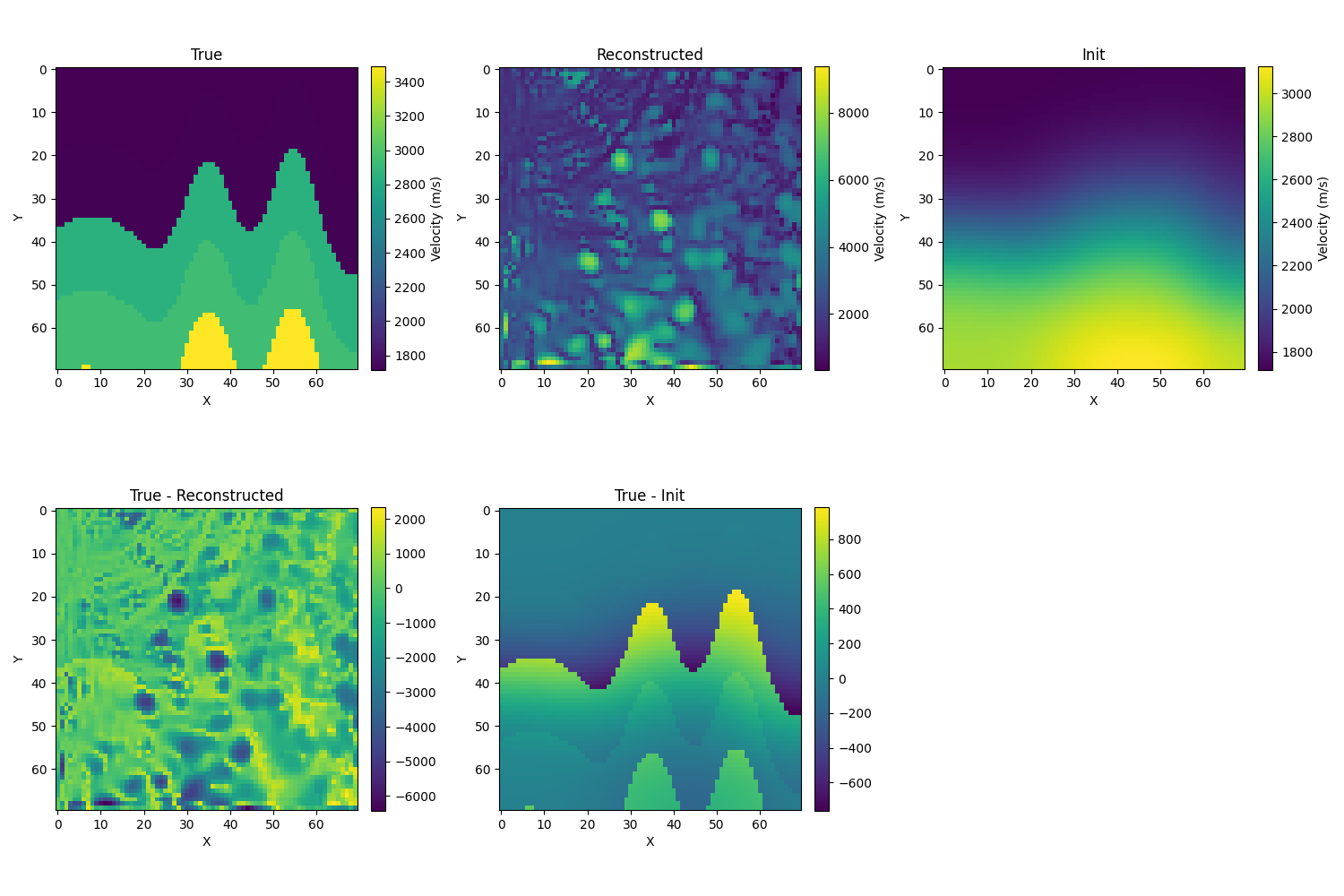
-
逐通道使用W2norm
- 取σ=10,结果如下,相对误差为3.7%
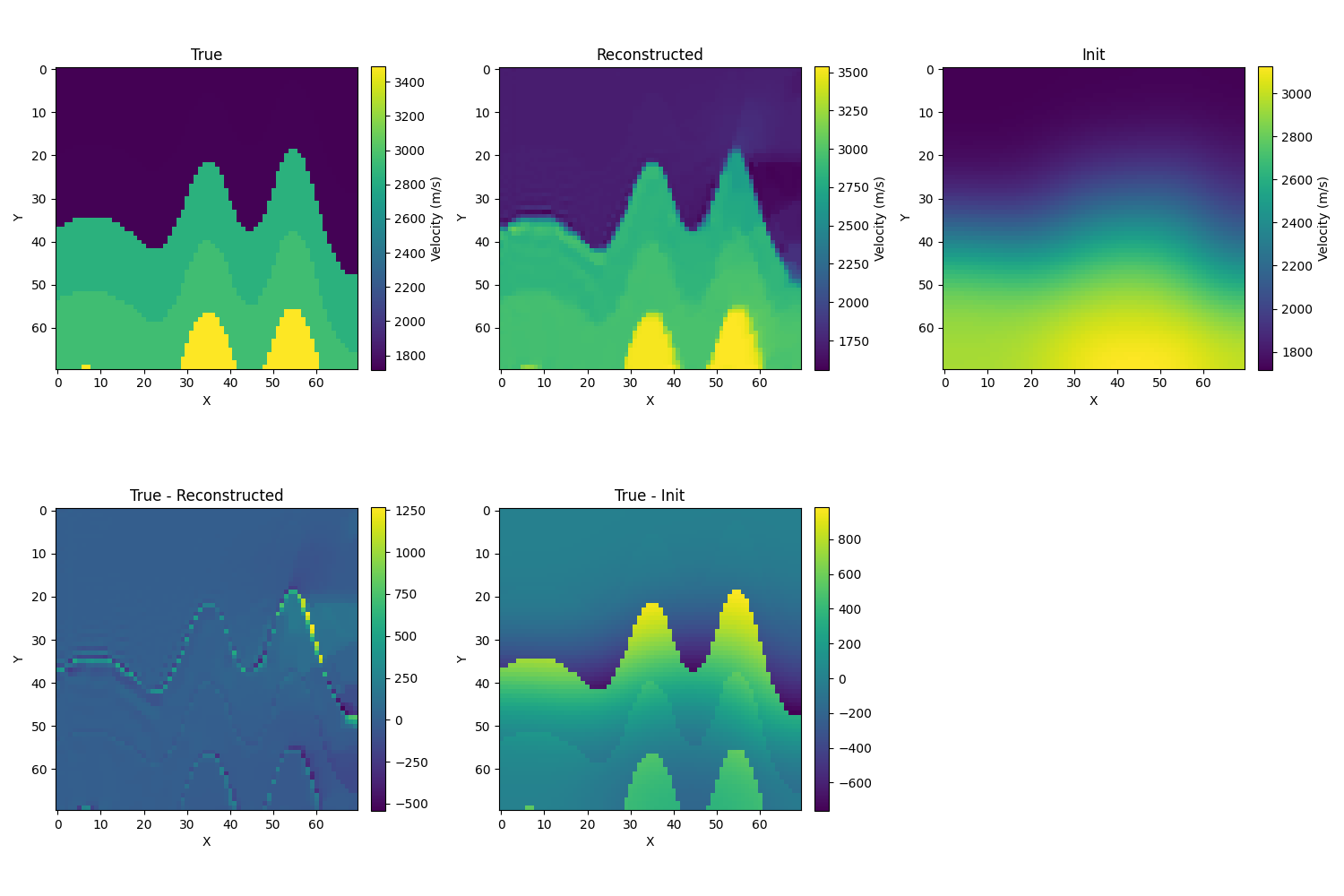
mse:
Sinkhorn:
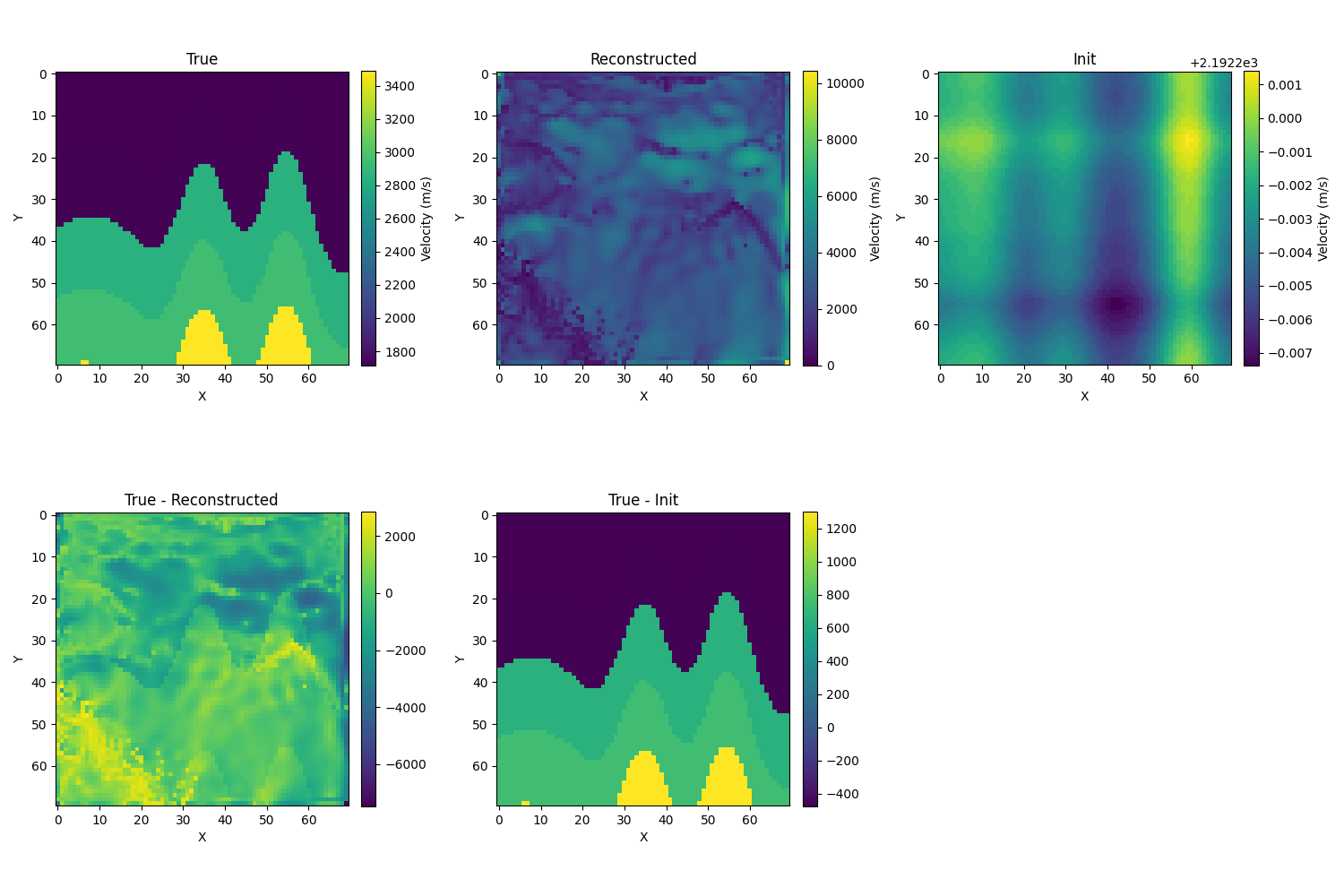
- 使用L2 norm
- Adam优化器:
- 初始化为真解的模糊化,取σ=10,初始相对误差为12.1%,迭代的结果如下,相对误差为8.8%,比震源和接收器都在左侧高。本来以为应该是比都放在左侧简单的,但实验结果好像不是这样的,并且出现了半收敛性?
-
取σ=100,还是寄
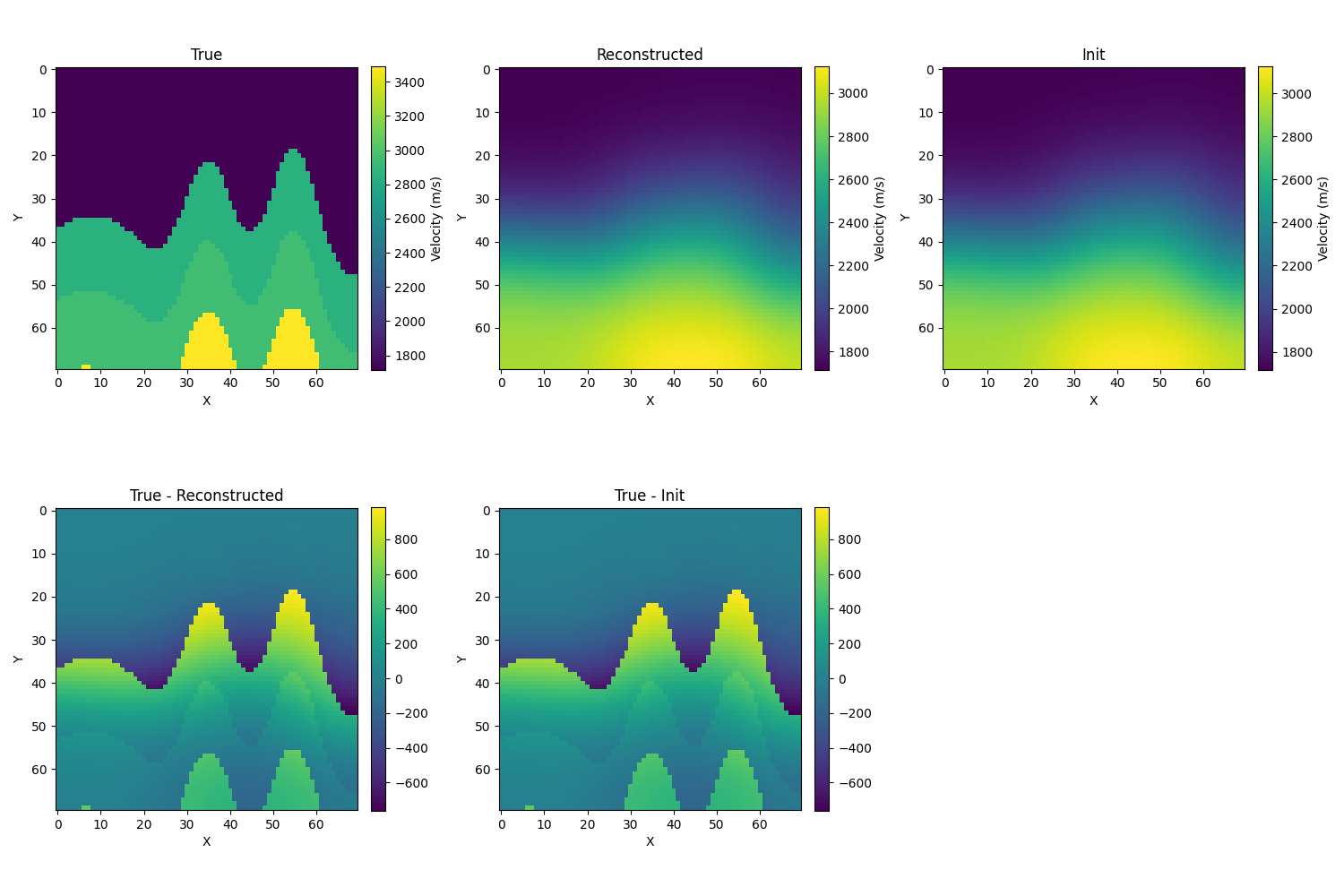
-
SGD:相对误差几乎不带降,也就是基本没做移动(这里我学习率设置为50),把学习率调到5000,loss开始降了,但相对误差几乎不变(应该是在局部极小点附近了)
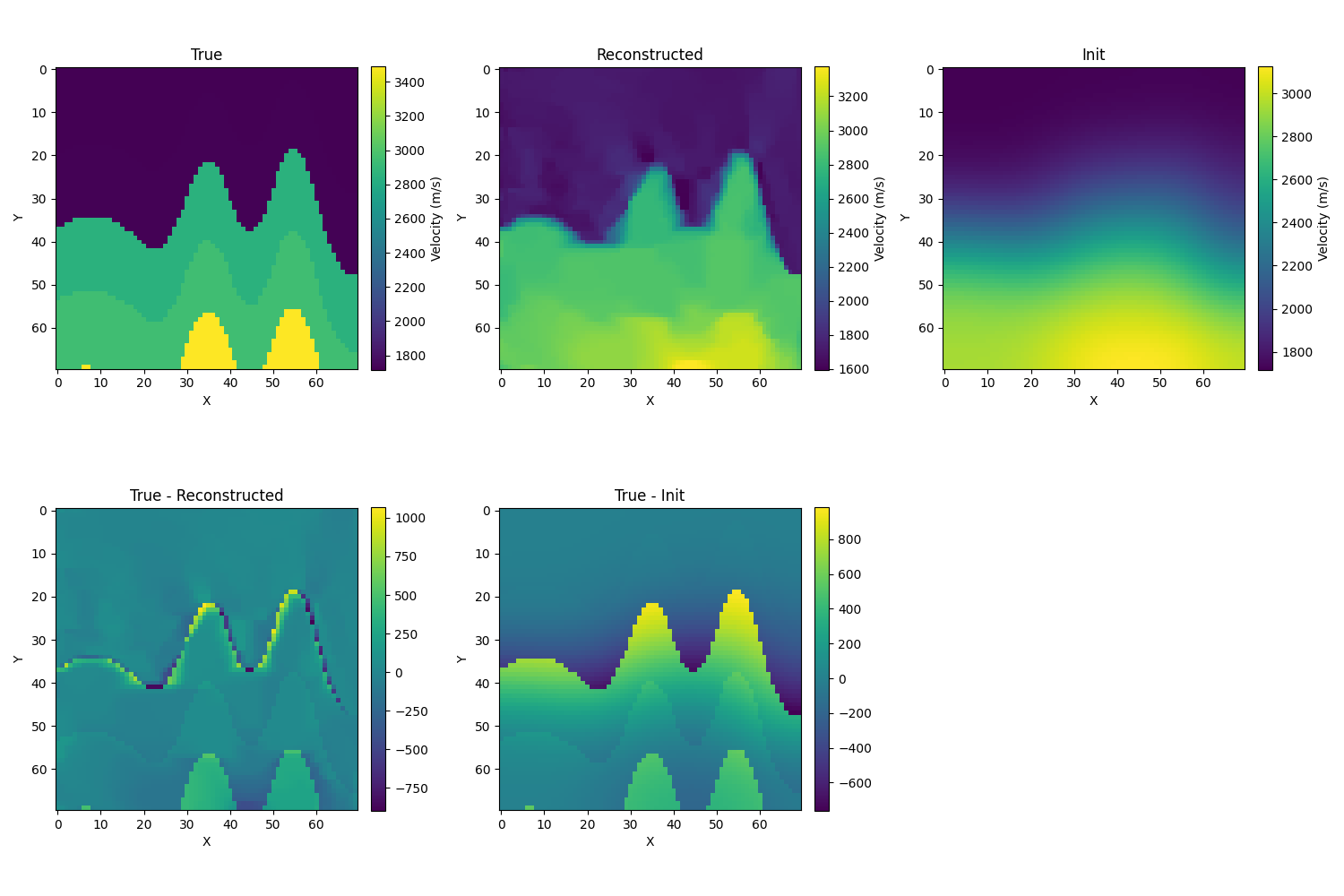
-
lbfgs优化(原来torch也是有lbfgs优化器的):我们继续重复上面的操作,如果使用默认的使用 strong_wolfe进行线搜索,也会出现上面和上面SGD同样的情况。自己实现的lbfgs,使用原步长结果也是不太能动。
-
使用W2 metric(以下用的Adam优化器)
- 使用sinkhorn:初始解依然设置为真解的模糊化,使用adam优化器,σ=10时出现了速度过小的情况,而且是在前几步就出现了这个问题,后面的结果也不收敛。
取σ=100,结果寄:
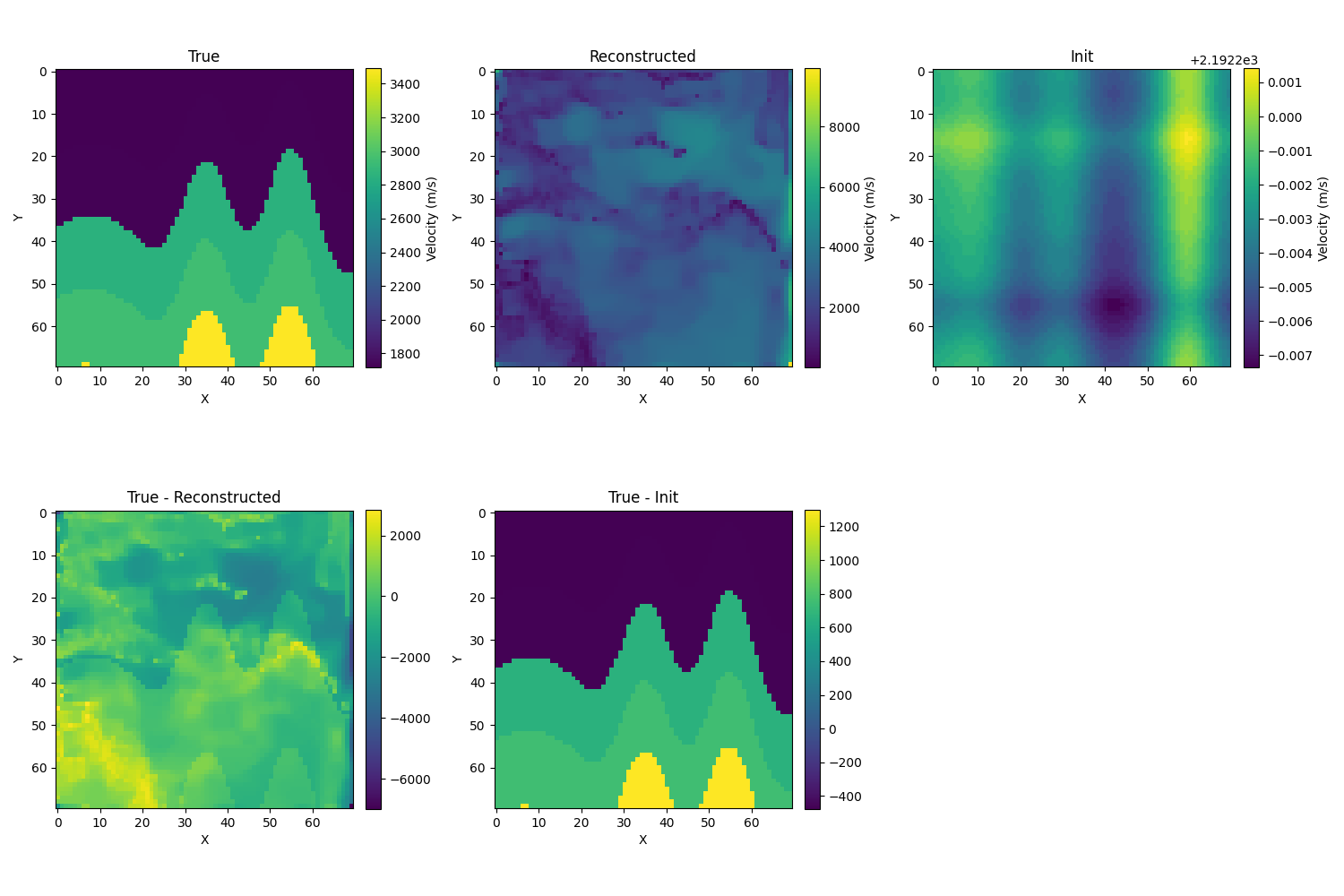
- 使用W2:(不如用MSE)
- 使用sinkhorn:(不管模糊化程度多少,这个都是寄)λ=1e−5得到的结果如下,相对误差大小为33.7%(寄):

-
使用MSE loss
- 初始化为真解的模糊化,取σ=10,初始相对误差为12.1%,迭代的结果如下,相对误差为8.7%,似乎也没有很简单
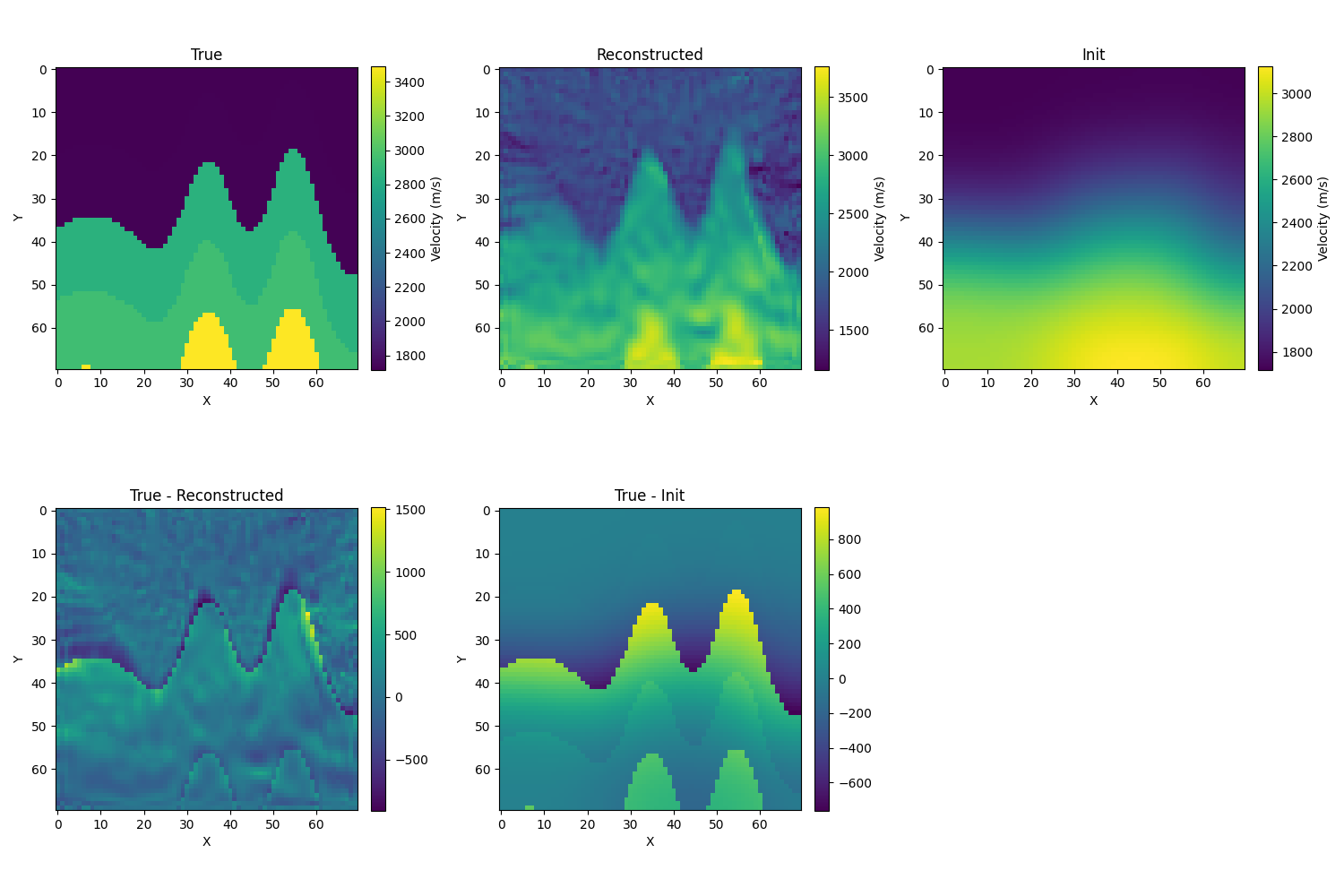
-
使用W2 metric(以下用的Adam优化器)
- 使用sinkhorn:初始解依然设置为真解的模糊化,使用adam优化器,σ=10时出现了速度过小的情况,而且是在前几步就出现了这个问题,后面的结果也不收敛。
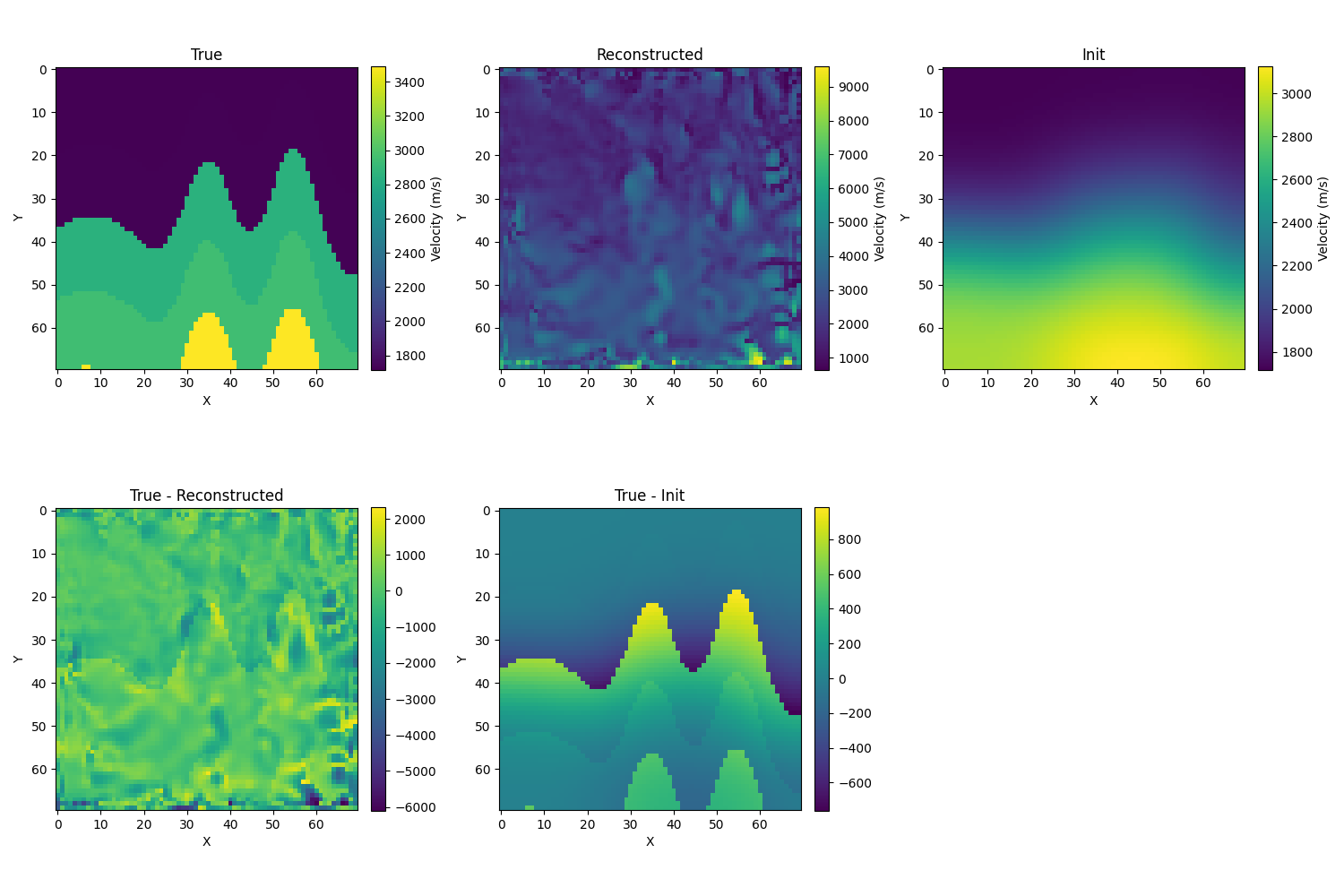
- 使用swd:1.σ=10,效果也还可以,相对误差大小为7.2%
-
使用MSE loss
- 初始化为真解的模糊化,取σ=10,λ=1e−6,初始相对误差为12.1%,迭代的结果如下,相对误差为7.5%
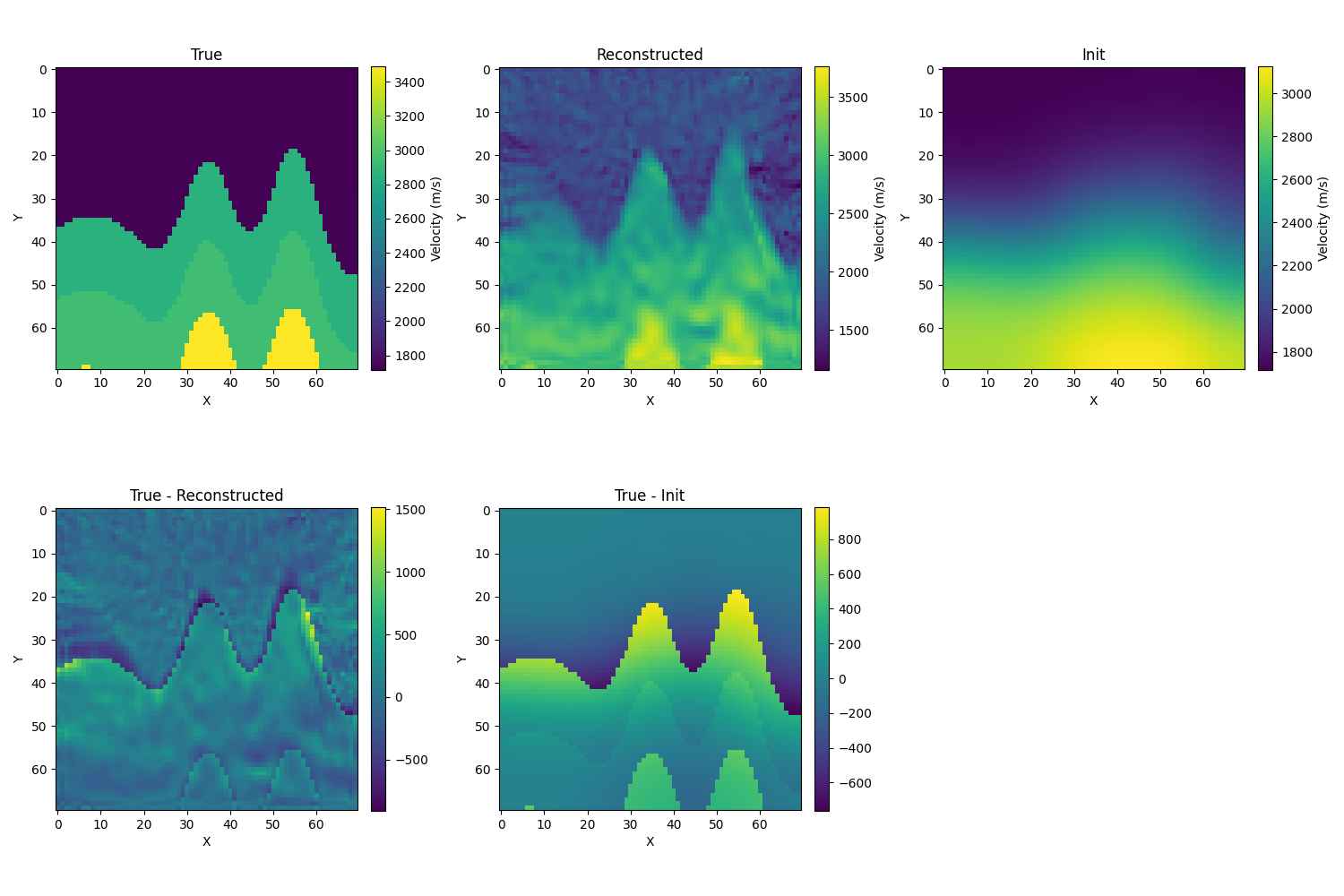
-
使用W2 metric(以下用的Adam优化器)
- 使用sinkhorn:初始解依然设置为真解的模糊化,使用adam优化器,σ=10时出现了速度过小的情况,而且是在前几步就出现了这个问题,后面的结果也不收敛。
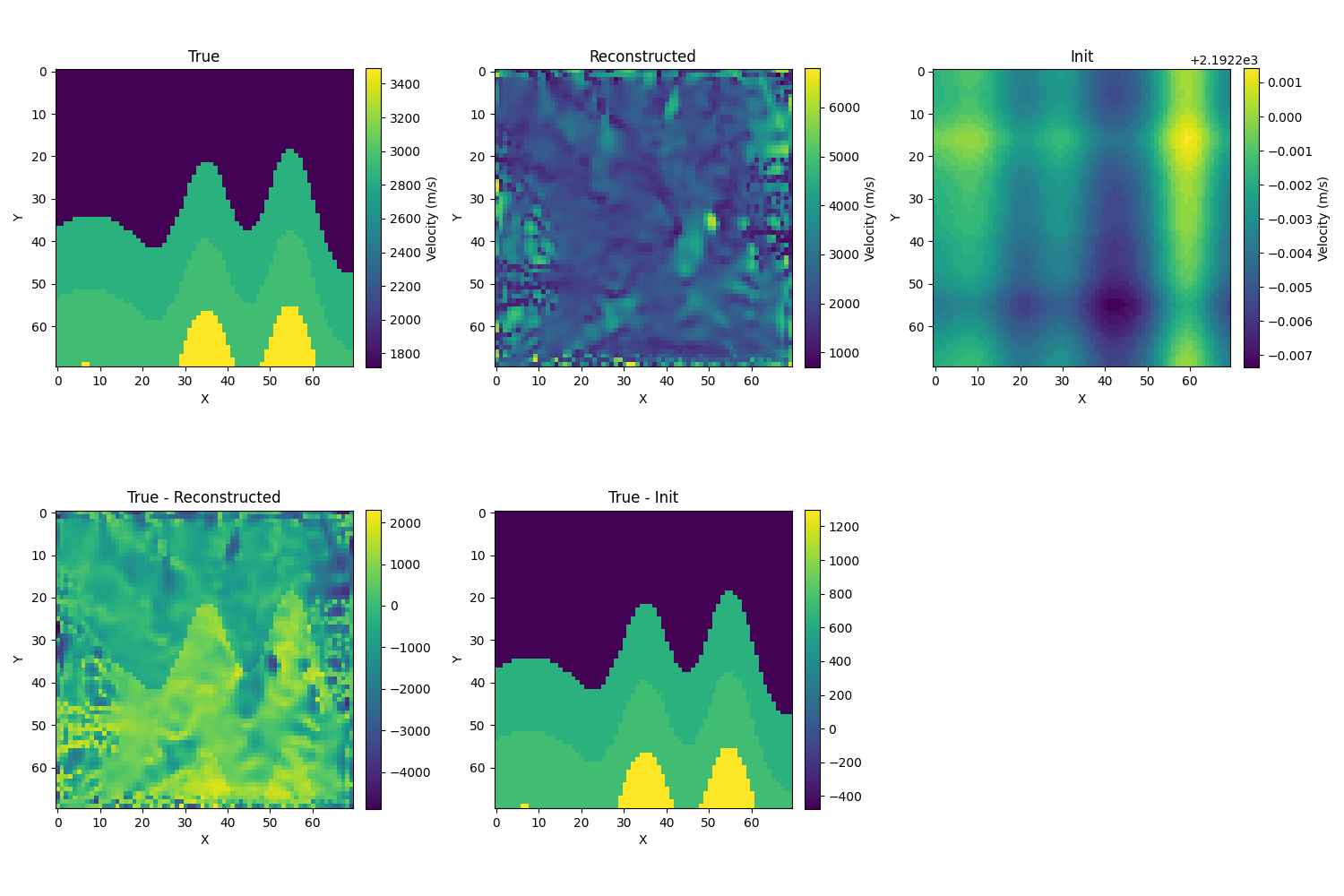
- 使用swd:1.σ=10,效果也还可以,相对误差大小为7.2%
-
使用MSE loss
- 初始化为真解的模糊化,取σ=10,初始相对误差为12.1%,迭代的结果如下,相对误差为7.0%
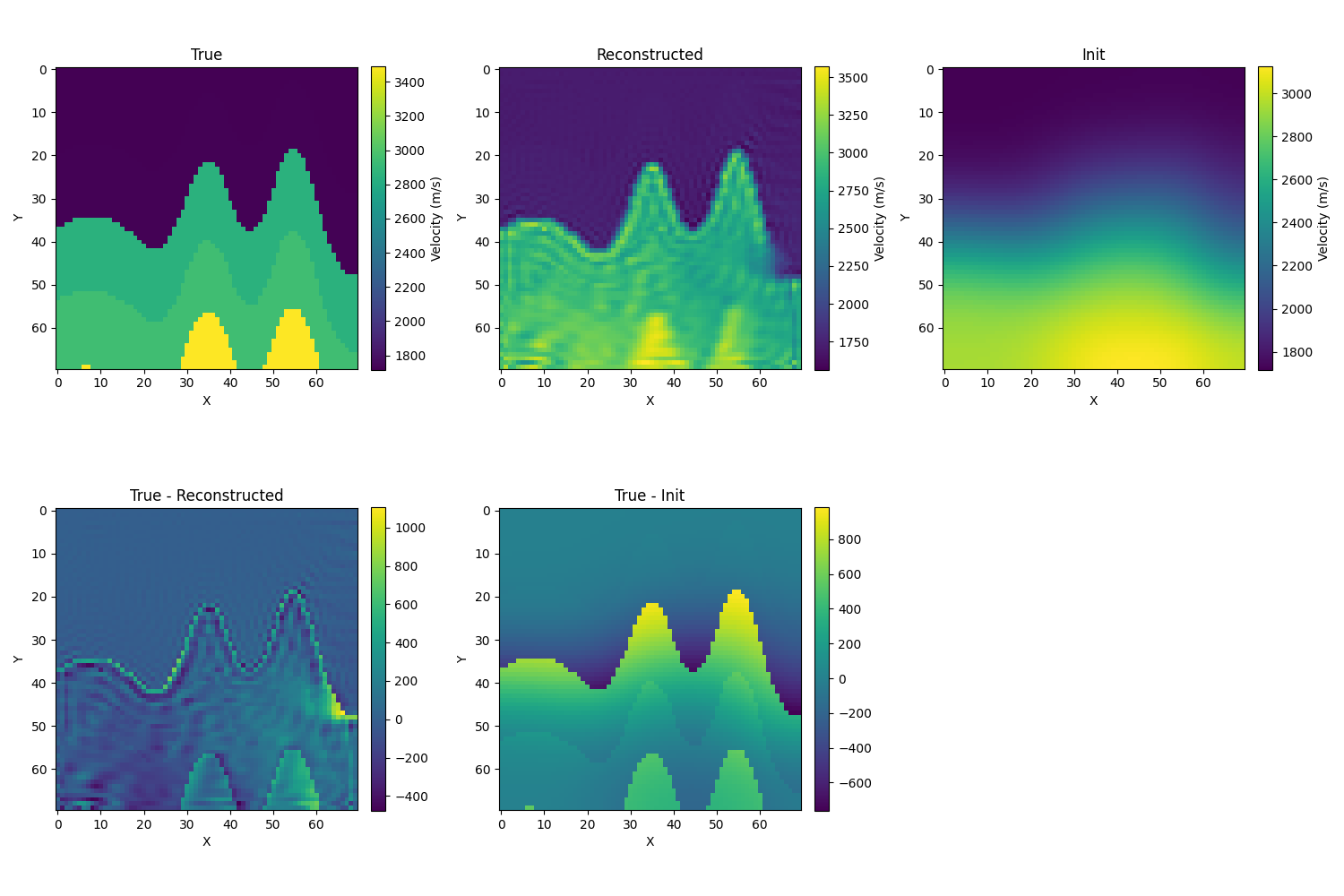
-
使用W2 metric(以下用的Adam优化器)
- 使用sinkhorn:初始解依然设置为真解的模糊化,使用adam优化器,σ=10时出现了速度过小的情况,而且是在前几步就出现了这个问题,后面的结果也不收敛。
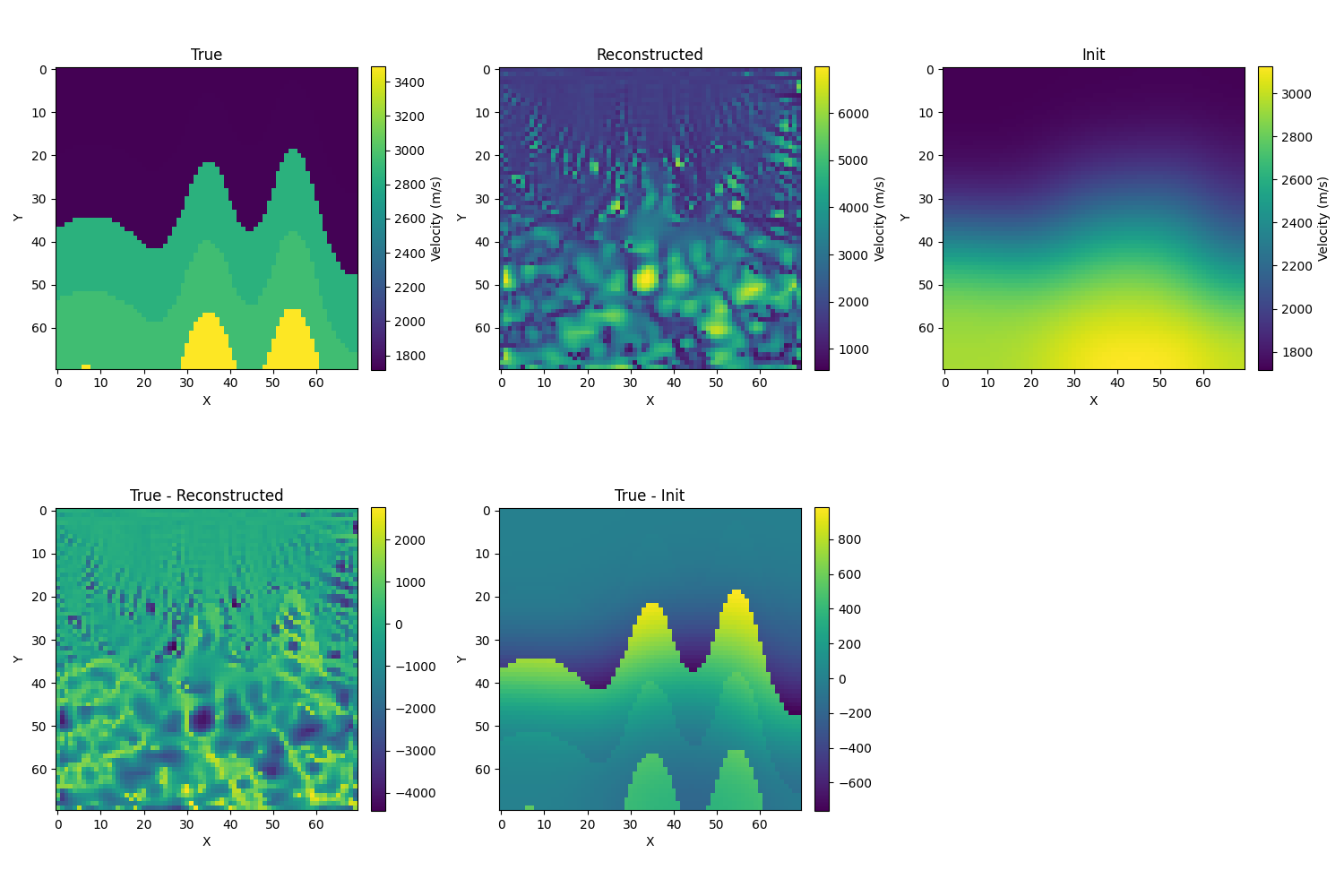
-
逐通道使用W2norm
- 初始化为真解的模糊化,取σ=10,初始相对误差为12.1%,迭代的结果如下,相对误差为4.2%
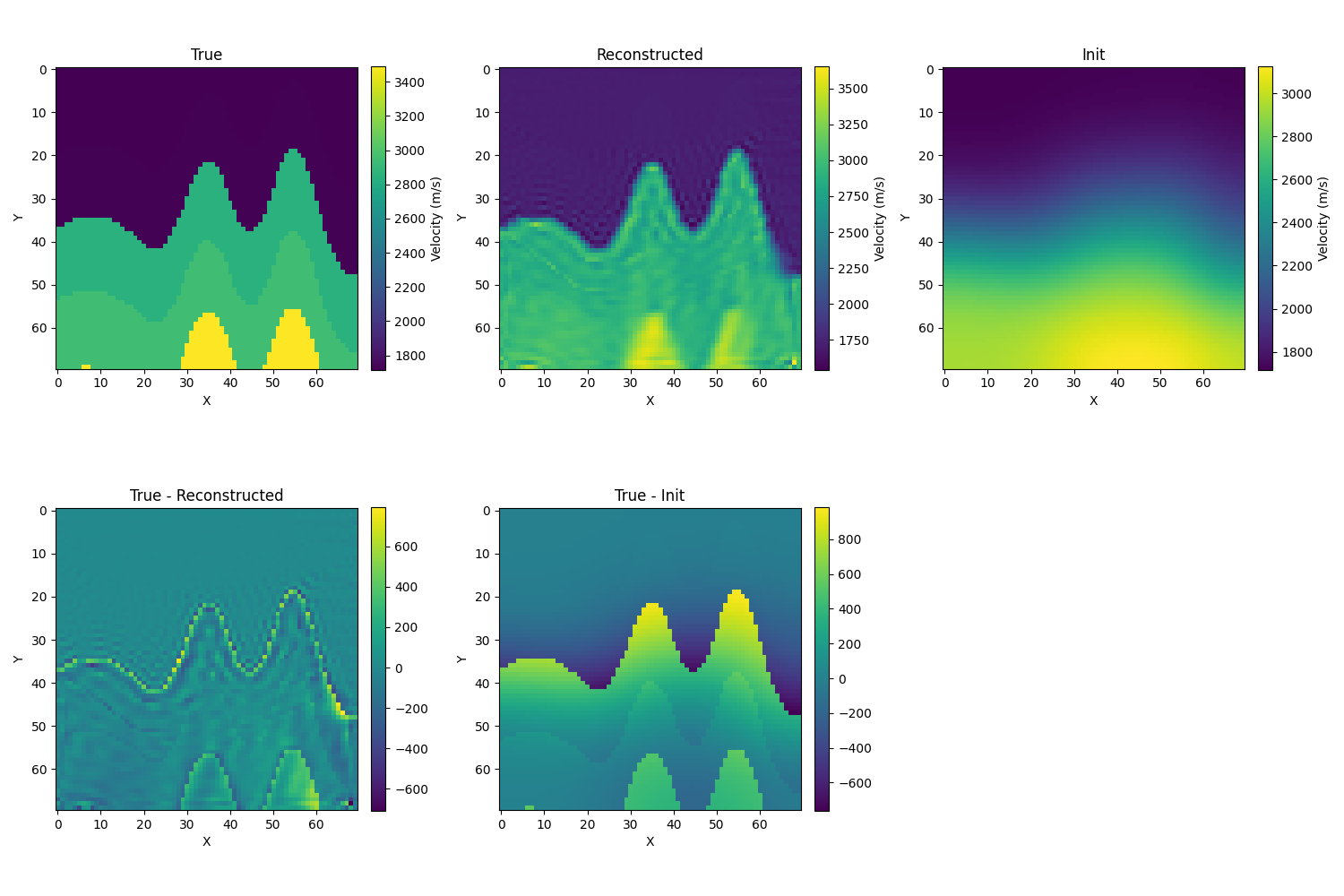
-
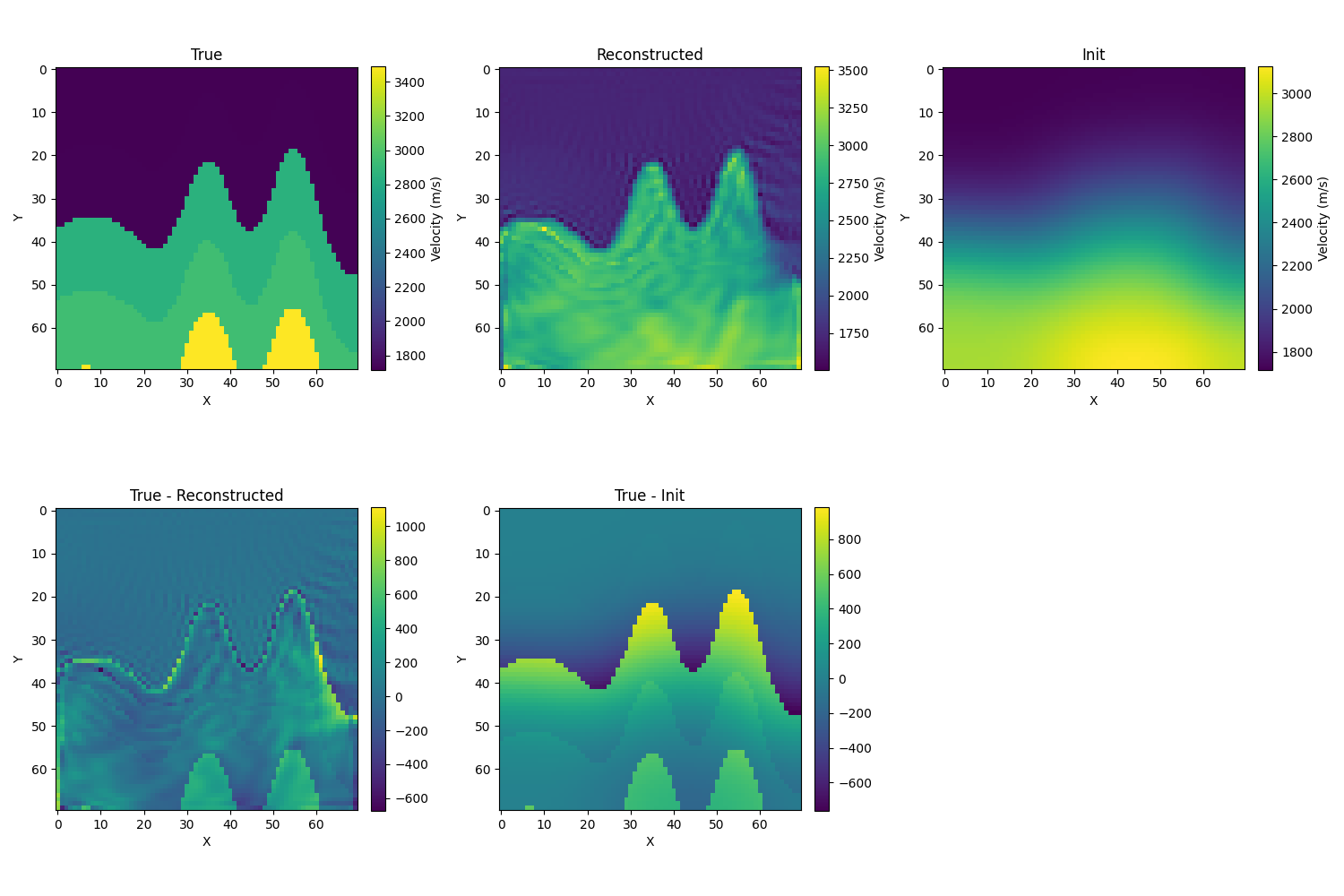
使用MSE loss
- 初始化为真解的模糊化,取σ=10,λ=1e−6,初始相对误差为12.1%,迭代的结果如下,相对误差为6.5%
-
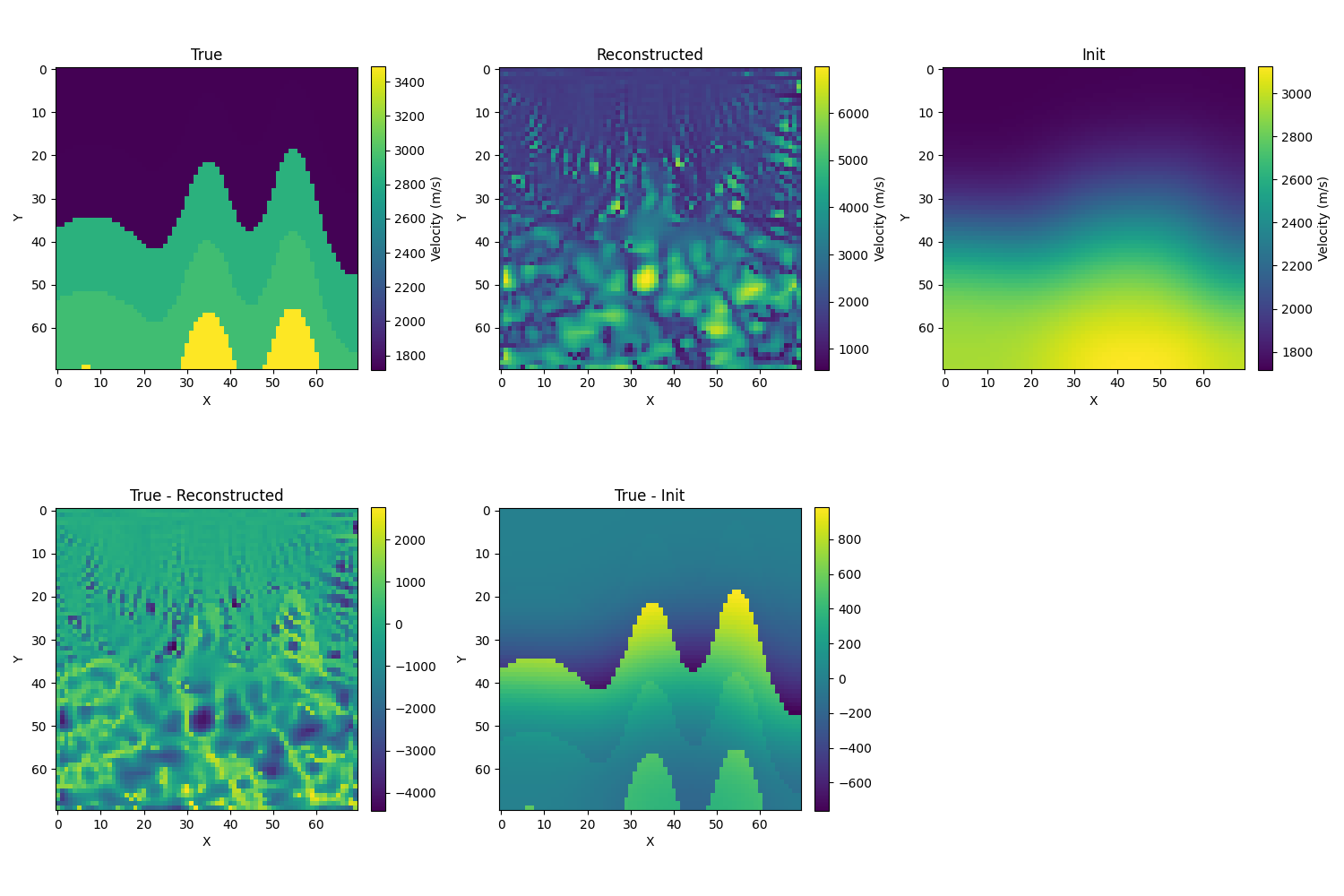
使用W2 metric(以下用的Adam优化器)
- 使用sinkhorn:初始解依然设置为真解的模糊化,使用adam优化器,σ=10时出现了速度过小的情况,而且是在前几步就出现了这个问题,后面的结果也不收敛。
-
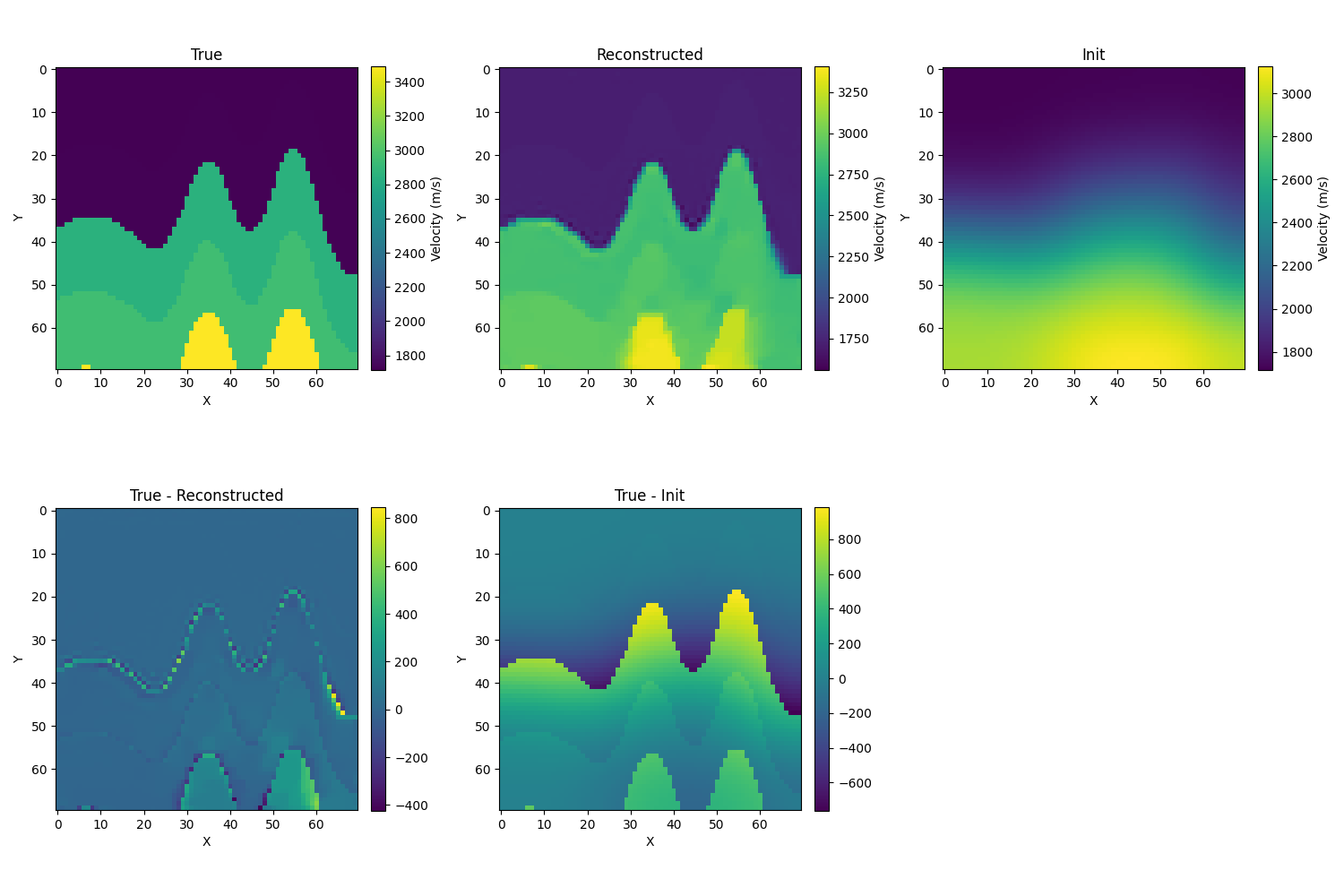
逐通道使用W2norm
- 初始化为真解的模糊化,取σ=10,λ=1e−6,初始相对误差为12.1%,迭代的结果如下,相对误差为3.2%
-
希尔伯特变换:
H{f(t)}=π1P.V.∫−∞+∞t−τf(τ)dτ=f(πt1)
其中P.V.代表柯西主值,定义如下(假设c处是奇点):
P.V.∫abf(x)dx=ε→0+lim[∫ac−εf(x)dx+∫c+εbf(x)dx]
希尔伯特变换相当于把信号所有频率分量相位推迟90度,对于f(t)=ei(wt+ϕ),H{f(t)}=ei(wt+ϕ−2π)
- 对于实信号f(t)解析信号
f^(t)=f(t)+iH{f(t)}
我们有如下定义:
- 瞬时振幅(也称为信号的包络):E(t)=[f(t)]2+[H{f(t)}]2
- 瞬时相位:Φ(t)=arctanf(t)H{f(t)}
- f^(t)=E(t)eiΦ(t)
 Home
Home